
Most organizations know they should be doing something with AI agents. Almost none have seen what a working one looks like from the inside, and that gap is costing them.
The phrase "AI agent" has become one of those terms that sounds impressive in a board presentation and means almost nothing in a Monday morning standup. Executives are hearing it from vendors, engineering teams are reading about it in newsletters, and somewhere in the middle, the people responsible for actually delivering product, are being asked to "explore what we can do with agents" without a clear picture of what they're exploring toward.
This article will make that picture concrete.
A Chatbot Answers. An Agent Acts.
The distinction matters because most organizations have already built or bought chatbots and called it AI adoption. A chatbot is reactive: you ask it a question, it responds. The interaction starts and ends with you.
An agent is different in a structural sense. It monitors for a condition, reasons over information when that condition is met, and then takes action, across multiple tools, without waiting for a human to initiate anything. The human doesn't start the chain. The chain starts itself.
That difference sounds simple. In practice, it changes what's possible.
What It Actually Looks Like
Here is a real workflow pattern, the kind that gets built in tools like Make.com when an R&D team decides to automate their sprint review process.
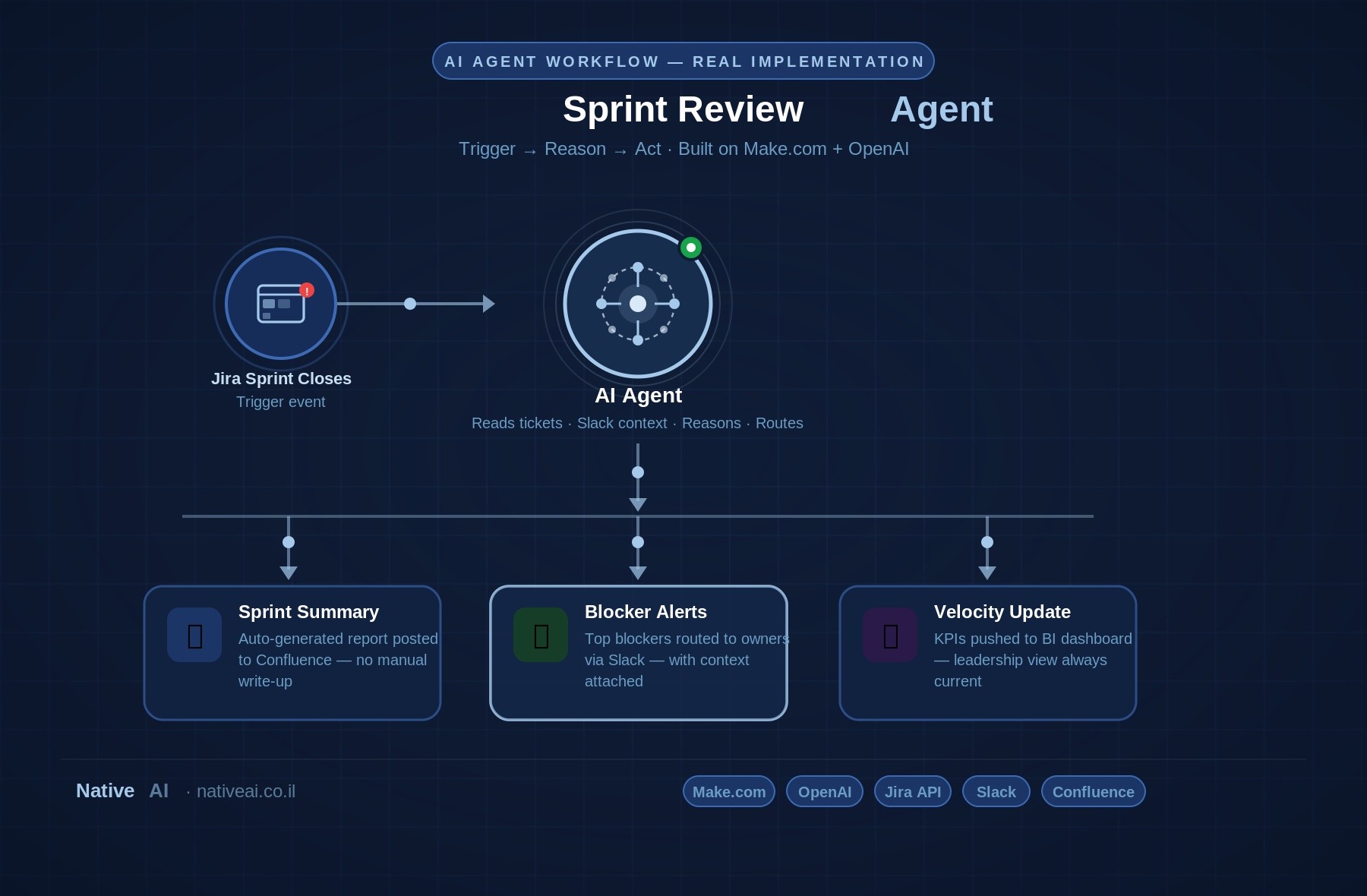
A sprint closes in Jira, this event is the trigger, nothing happens until it fires.
When it does, an AI agent pulls the full ticket data from that sprint: what was completed, what was blocked, what slipped and why. It cross-references the relevant Slack threads from that two-week period. It reads the commit log context. Then it reasons over all of that data and produces three outputs simultaneously.
The first: a structured sprint summary, written in prose, posted directly to Confluence. Not a template filled in by hand, a document that reads like a senior engineer wrote it, because the agent has enough context to distinguish a missed ticket caused by scope creep from one caused by an external dependency.
The second: a set of blocker alerts routed to the specific people who own the blocked items, sent via Slack, with the relevant context attached. Not a generic "you have blockers" notification, a message that explains what's stuck and why, addressed to the person who can actually do something about it.
The third: an update to the velocity dashboard, pushing the sprint's KPIs to wherever leadership tracks delivery health.
From trigger to all three outputs, no human opened a spreadsheet. No one chased down status updates. No retrospective meeting was scheduled just to collect information that already existed in the tools.
The technology stack for this is not exotic. Make.com handles the workflow orchestration. The Jira API provides the ticket data. Slack and Confluence are connected as destinations. An LLM sits in the middle, doing the reasoning and writing.
The total build time for a workflow like this, in an organization with clean Jira hygiene, is measured in days, not months.
The Part That's Actually Hard
The technology is not the bottleneck. That's the thing most AI implementation conversations get wrong.
The hard part is deciding which workflow to touch first, and being honest about why that choice matters more than the tools you use to build it.
Not every process is a good candidate for an agent. The workflows that work well share a common structure: there is a clear trigger, the data the agent needs already exists in digital form somewhere in your toolstack, and the output has a defined destination.
Sprint reviews fit this structure almost perfectly, so do release note generation, incident summaries, onboarding checklists, and weekly delivery digests. These are processes where the raw material: tickets, commits, messages, logs is already there. The agent's job is to reason over it and produce something useful.
The workflows that fail are usually the ones where the trigger is ambiguous, the data is in someone's head or a PDF attached to an email, or the output requires a judgment call that depends on organizational context no tool has access to. Automating those processes doesn't fail because the technology is weak, it fails because the process itself wasn't clean enough to automate.
This is why the first question in any agent implementation isn't "what tool should we use?" It's "which of our workflows already has the right shape?"
The answer to that question is almost always found by looking at the things your team does repeatedly, at a predictable cadence, using data that lives in your existing systems.
What Changes When an Agent Is Running
There is a second order effect that most organizations don't anticipate until they've lived with an agent for a few weeks.
When the sprint summary writes itself, something subtle shifts in how the team uses information. The summary exists before anyone asks for it. The blockers surface before the weekly sync. The velocity data is current before the leadership review starts. The team stops spending cognitive energy on producing status information and starts spending it on acting on status information.
This is not a small change. In a team of 20 engineers, the hours spent each sprint on manual reporting, update chasing, and status formatting add up to something significant, but more importantly, those hours have a quality cost, not just a quantity cost. They're hours spent on low-value work by people hired for high-value thinking.
The agent doesn't replace those people. It eliminates the part of their week that was never a good use of them in the first place.
The Question Worth Asking
Every R&D organization running more than 20 people has at least five workflows with the right structure for automation. They exist right now, inside your Jira, your Slack, your Confluence, your incident log. They're being done manually not because automation is too hard, but because no one has looked at them specifically through the lens of: does this have a trigger, does the data already exist, does the output have a clear destination?
That's the lens, apply it to your sprint review process, then to your release notes, then to your weekly delivery digest.
The question isn't whether AI agents can work in your organization, it's which workflow you're going to start with.



